
Improving customer support efficiency is a key challenge for every successful business. Processing and tracking error reports is often a time-consuming process that can divert valuable resources from other important tasks. In this tutorial, we will demonstrate how to create an AI agent that automatically monitors Gmail accounts, detects customer error reports, analyzes their content, and then creates the appropriate Jira tickets.
This system automatically processes incoming emails and creates Jira tickets from them. Here’s how it works step by step:
- Email Monitoring: The system checks for and downloads unread emails with attachments and their history every 30 seconds. The system changes the status of the email to “read” so it won’t be processed again in future runs
- AI Analysis: An artificial intelligence analyzes the emails to understand their content.
- Project Identification: The system first queries the available Jira projects so the AI can identify which project the email belongs to.
- Information Extraction: The AI extracts the necessary data from the email to create a Jira ticket.
- Automatic Feedback: If the information is unclear or incomplete, the AI automatically writes a reply to the sender requesting more details. The email then remains unprocessed. When the sender responds, the reply email arrives as unread, so the system processes it again later.
- Ticket Creation: If all necessary information is available, the system automatically creates the appropriate Jira ticket through the JIRA REST API and attaches the email attachments as well.
Implemantation:
You’ll need the following packages:
pip install python-dotenv langchain langchain-anthropic langgraph google-api-python-client google-auth-oauthlib requests fastapi uvicorn apschedulerThe below code implements a Gmail integration using the Google API. It authenticates with Google’s services through the get_authentication() function, which manages OAuth credentials, storing and refreshing tokens as needed. The core functionality revolves around get_unread_messages_with_threads(), which retrieves unread customer emails, automatically marks them as read, and collects their complete conversation history. Messages are processed by extract_mail(), which pulls out critical metadata like subject, sender, and timestamp. The get_message_body_and_attachments() function handles parsing both plain text and HTML content while identifying attachments. When attachments are present, download_attachment() can save them locally or return the binary data. Finally, the reply_to_thread() function enables automated responses to email threads, properly formatting replies with appropriate headers and references to maintain conversation context. Together, these functions create a comprehensive system for monitoring, processing, and responding to customer communications via Gmail.
import os
import os.path
import base64
import re
from email.mime.text import MIMEText
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from googleapiclient.errors import HttpError
# If modifying these scopes, delete the token.json file
SCOPES = ['https://www.googleapis.com/auth/gmail.readonly', 'https://www.googleapis.com/auth/gmail.modify']
def get_authentication():
"""
Handles the authentication process with Google API
Returns an authenticated service object
"""
creds = None
# The file credentials.json stores the user's access and refresh tokens
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
# If there are no valid credentials, let the user log in
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open('token.json', 'w') as token:
token.write(creds.to_json())
return build('gmail', 'v1', credentials=creds)
def get_unread_messages_with_threads(user_id='me', label_ids=None, max_results=20):
"""
Retrieves unread messages with the specified label, including their complete history and the text of the original messages.
Args:
user_id: The user's email address or 'me' for the authenticated user.
label_ids: List of desired label identifiers.
max_results: Maximum number of messages to retrieve.
Returns:
List of unread messages with their complete history, the text of the original messages, and their attachments.
"""
try:
service = get_authentication()
response = service.users().messages().list(
userId=user_id,
labelIds=label_ids,
q='is:unread',
maxResults=max_results
).execute()
messages = []
if 'messages' not in response:
print("There are no unread messages with the specified label.")
return messages
for msg in response['messages']:
email_conversation = []
service.users().messages().modify(
userId=user_id,
id=msg["id"],
body={'removeLabelIds': ['UNREAD'],'addLabelIds': []}
).execute()
if msg.get('threadId'):
thread = service.users().threads().get(userId=user_id, id=msg['threadId']).execute()
for message in thread['messages']:
extract_mail(email_conversation, message)
else:
extract_mail(email_conversation, msg)
messages.append({
'email_conversation': email_conversation,
'subject': email_conversation[0]['subject'] if email_conversation else 'N/A',
'email_id': msg.get('threadId'),
'has_attachments': any(len(msg['attachments']) > 0 for msg in email_conversation)
})
return messages
except HttpError as error:
print(f"Error: {error}")
return []
def extract_mail(email_conversation, message):
msg_id = message['id']
payload = message['payload']
headers = payload.get('headers', [])
subject = next((header['value'] for header in headers if header['name'] == 'Subject'), 'N/A')
from_email = next((header['value'] for header in headers if header['name'] == 'From'), 'N/A')
date = next((header['value'] for header in headers if header['name'] == 'Date'), 'N/A')
email_id = msg_id
body, attachments = get_message_body_and_attachments(payload, msg_id)
email_conversation.append({
'email_id': email_id,
'subject': subject,
'from': from_email,
'date': date,
'body': body,
'attachments': attachments
})
def get_message_body_and_attachments(payload, msg_id):
"""
Extracts the message body and attachments from the payload.
Args:
Returns:
Tuple containing:
- The message body as text.
- List of attachments (filename, size, mime-type, attachment_id).
"""
body = ''
attachments = []
def process_parts(parts):
nonlocal body
nonlocal attachments
for part in parts:
mime_type = part.get('mimeType', '')
# If this is a text partRetryClaude can make mistakes. Please double-check responses.
if mime_type == 'text/plain' and not body: # Csak akkor állítjuk be a body-t, ha még nincs
data = part.get('body', {}).get('data')
if data:
body = base64.urlsafe_b64decode(data.encode('ASCII')).decode('utf-8')
# If this is an HTML part and we don't have a text body yetRetryClaude can make mistakes. Please double-check responses.
elif mime_type == 'text/html' and not body:
data = part.get('body', {}).get('data')
if data:
# Extract text from HTML
html_body = base64.urlsafe_b64decode(data.encode('ASCII')).decode('utf-8')
body = html_body
elif 'filename' in part.get('body', {}) or 'attachmentId' in part.get('body', {}):
filename = part.get('filename', 'unnamed_attachment')
body_data = part.get('body', {})
attachment_id = body_data.get('attachmentId')
attachments.append(download_attachment(
service=get_authentication(),
attachment_id=attachment_id,
message_id=msg_id,
user_id="me",
save_path=f"./files/{filename}"
))
if 'parts' in part:
process_parts(part['parts'])
if 'parts' in payload:
process_parts(payload['parts'])
else:
mime_type = payload.get('mimeType', '')
if mime_type == 'text/plain' or mime_type == 'text/html':
data = payload.get('body', {}).get('data')
if data:
body = base64.urlsafe_b64decode(data.encode('ASCII')).decode('utf-8')
return body, attachments
def download_attachment(service, user_id, message_id, attachment_id, save_path=None):
"""
Downloads the attachment from the specified message.
Args:
service: The Gmail API service.
user_id: The user ID.
message_id: The message ID.
attachment_id: The attachment ID.
save_path: The save location. If None, just returns the bytes.
Returns:
The attachment in bytes form, or the file path if save_path is specified.
"""
try:
attachment = service.users().messages().attachments().get(
userId=user_id,
messageId=message_id,
id=attachment_id
).execute()
data = attachment.get('data')
if not data:
return None
file_data = base64.urlsafe_b64decode(data.encode('UTF-8'))
if save_path:
with open(save_path, 'wb') as f:
f.write(file_data)
return save_path
else:
return file_data
except Exception as error:
print(f"Error: {error}")
return None
def reply_to_thread(thread_id, message_text):
service = get_authentication()
thread = service.users().threads().get(userId="me", id=thread_id).execute()
messages = thread.get('messages', [])
last_message = messages[-1]
headers = {h['name']: h['value'] for h in last_message['payload']['headers']}
# Extract a clean email address
email_address = re.search(r'[\w.-]+@[\w.-]+', headers['From']).group()
# Prepare the reply message
reply_msg = MIMEText(message_text)
reply_msg['To'] = email_address
reply_msg['Subject'] = "Re: " + headers['Subject']
reply_msg['In-Reply-To'] = headers['Message-ID']
reply_msg['References'] = headers['Message-ID']
# Encode and send message
raw_message = base64.urlsafe_b64encode(reply_msg.as_bytes()).decode()
message = {'raw': raw_message, 'threadId': thread_id}
sent_message = service.users().messages().send(userId="me", body=message).execute()
print(f"Message sent! ID: {sent_message['id']}")As the next step, let’s write the Jira integration. You will need a Jira token from here, which you can create at: https://id.atlassian.com/manage-profile/security/api-tokens. The get_session() function creates an authenticated session using environment variables for the Jira username and API key. The get_projects() function retrieves a list of available Jira projects, returning their IDs and names.
The attach_to_issue() function uploads a file attachment to an existing Jira issue by specifying the issue key and the local file path. It handles opening the file in binary mode and properly configuring the request headers. create_jira_issue(), creates a new Jira issue with a specified title, project ID, and description. The function also supports attaching multiple files to the newly created issue by calling the attach_to_issue() function for each attachment path provided.
def get_session():
session = requests.Session()
session.auth = (os.getenv("JIRA_USER"), os.getenv("JIRA_API_KEY"))
return session
def get_projects():
url = f"https://{os.getenv('JIRA_DOMAIN')}.atlassian.net/rest/api/3/project/search"
response = get_session().get(url)
projects = []
if response.status_code == 200:
response_json = response.json()
for project in response_json["values"]:
projects.append({"id": project["id"], "name": project["name"]})
else:
print(response.status_code)
print(response.text)
return projects
def attach_to_issue(issue_key: str, attachment_path: str) -> Dict:
"""Attach a file to an existing Jira issue
Args:
issue_key: The key of the issue (e.g., 'PROJ-123')
attachment_path: Path to the file to be attached
Returns:
Response data from the attachment request
"""
url = f"https://{os.getenv('JIRA_DOMAIN')}.atlassian.net/rest/api/3/issue/{issue_key}/attachments"
headers = {
"X-Atlassian-Token": "no-check"
}
with open(attachment_path, 'rb') as file:
files = {'file': (os.path.basename(attachment_path), file)}
session = get_session()
response = session.post(url, headers=headers, files=files)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"Failed to attach file: {response.status_code} Error: {response.text}")
def create_jira_issue(issue_name: str, project_id: str, description: str,
attachments: Optional[List[str]] = None) -> Dict:
"""
Create a Jira issue with the provided parameters
Args:
issue_name: Title of the issue
project_id: ID of the project in Jira
description: Detailed description of the issue
attachments: List of file paths to attach to the issue
Returns:
Dictionary with the created issue's key and ID
"""
url = f"https://{os.getenv('JIRA_DOMAIN')}.atlassian.net/rest/api/3/issue"
if attachments is None:
attachments = []
issue_data = {
"fields": {
"summary": issue_name,
"project": {"id": project_id},
"description": {
"type": "doc",
"version": 1,
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": description
}
]
}
]
},
"issuetype": {"id": "10002"},
},
"update": {}
}
session = get_session()
response = session.post(url, json=issue_data)
if response.status_code in (200, 201):
issue = response.json()
print(f"Issue created successfully: {issue['key']}")
if attachments:
for attachment_path in attachments:
attach_to_issue(issue["key"], attachment_path)
return issue
else:
raise Exception(f"Failed to create issue: {response.status_code} Error: {response.text}")Now that the necessary integrations are in place, it’s time to build the AI Agentic workflow. It is structured in the following way. The issue_data_agent analyzes the incoming customer email and also receives the Jira project list, then tries to identify the essential information – such as the project identifier, the problem name and description, and decides whether we have enough information to create a ticket or if additional data is needed.
When all necessary information is available, the create_issue_ticket() function automatically creates a Jira ticket, attaching the information and attachments found in the email. However, if some important data is missing, the create_email_response_agent writes an email to the customer, explaining exactly what additional information the support team needs.
The router() function decides which direction the process should continue – either it takes the „create_ticket” route and creates a bug ticket, or it chooses the „request_more_info” route and requests additional information.
import os
from typing import List, TypedDict, Literal, Dict, Any
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import SecretStr
from langgraph.graph import StateGraph, END
from jira import get_projects, create_jira_issue
from mail import reply_to_thread
class State(TypedDict):
email_id: str
email_conversation: List[Dict[str, Any]]
current_mail: str
need_more_information: bool
project_id: str
issue_name: str
description: str
additional_info_needed: str
response_mail: str
mail_subject: str
def get_model():
return ChatAnthropic(
anthropic_api_key=SecretStr(os.getenv('ANTHROPIC_API_KEY')),
model="claude-3-7-sonnet-20250219"
)
def create_issue_data_agent():
prompt_str = """
You are an assistant that extracts issue information from customer emails to create issue tickets.
# Instructions
1. Analyze the customer email to extract all necessary information.
2. Extract the project ID by matching information in the email with the provided project list. Be flexible with partial matches or descriptions.
3. Extract other required fields: issue name, issue description
4. Only set need_more_information to true if critical information cannot be determined after attempting reasonable inference.
5. When need_more_information is true, provide a specific description in additional_info_needed about exactly what information is missing.
# Available Projects
<projects>
{projects}
</projects>
# Mail subject
<mail_subject>
{subject}
</mail_subject>
# Emails
<history>
{email_history}
</history>
# Response Format
Return a JSON object that follows the IssueData structure:
{{
"need_more_information": boolean, // only true if critical information cannot be determined
"project_id": string, // matching project ID
"name": string, // concise issue name/title
"description": string, // detailed issue description
"additional_info_needed": string // specific description of missing information, empty if not needed
}}
"""
prompt = PromptTemplate(template=prompt_str, input_variables=["projects", "email_history", "subject"])
return prompt | get_model() | JsonOutputParser()
def create_email_response_agent():
prompt_str = """
You are a helpful customer support agent responding to a customer's issue report.
Your task is to craft a professional and empathetic email requesting the additional information needed to properly address their issue.
# Conversation
<history>
{email_conversation}
</history>
# The information that is needed
<additional_info_needed>
{additional_info_needed}
</additional_info_needed>
# Instructions
1. Start with a polite greeting and thank the customer for their message.
2. Acknowledge their issue briefly to show understanding.
3. Explain that you need additional information to proceed with resolving their issue.
4. Clearly list the specific information needed as mentioned in the additional_info_needed section.
5. Provide a clear explanation for why this information is necessary.
6. End with a friendly closing, including your name and support team.
7. Keep the tone professional, helpful, and empathetic.
8. Use simple, clear language that is easy to understand.
# Response Format
Write a complete email response that follows the above instructions.
Do not use placeholders or template variables in your response.
"""
prompt = PromptTemplate(template=prompt_str,
input_variables=["email_conversation", "additional_info_needed"])
return prompt | get_model() | StrOutputParser()
def extract_issue_data(state: State) -> State:
"""Extract issue data from the customer email"""
projects = get_projects()
issue_data_agent = create_issue_data_agent()
result = issue_data_agent.invoke({
"projects": "\n".join([f"{p['id']}: {p['name']}" for p in projects]),
"email_history": [conv["body"] for conv in state["email_conversation"]],
"subject": state["mail_subject"]
})
state["need_more_information"] = result["need_more_information"]
state["project_id"] = result["project_id"]
state["issue_name"] = result["name"]
state["description"] = result["description"]
state["additional_info_needed"] = result["additional_info_needed"]
return state
def create_issue_ticket(state: State) -> State:
"""Create an issue ticket in the system"""
attachments = []
for conv in state["email_conversation"]:
attachments.extend(conv["attachments"])
create_jira_issue(
issue_name=state['issue_name'],
description=state['description'],
project_id=state['project_id'],
attachments=attachments,
)
return state
def generate_more_info_email(state: State) -> State:
"""Generate an email requesting more information"""
email_response_agent = create_email_response_agent()
response = email_response_agent.invoke({
"email_conversation": [conv["body"] for conv in state["email_conversation"]],
"additional_info_needed": state["additional_info_needed"]
})
reply_to_thread(thread_id=state["email_id"], message_text=response)
return state
def router(state: State) -> Literal["create_ticket", "request_more_info"]:
"""Route based on whether more information is needed"""
if state["need_more_information"]:
return "request_more_info"
else:
return "create_ticket"
def build_issue_workflow_graph():
workflow = StateGraph(State)
workflow.add_node("extract_issue_data", extract_issue_data)
workflow.add_node("create_ticket", create_issue_ticket)
workflow.add_node("request_more_info", generate_more_info_email)
workflow.set_entry_point("extract_issue_data")
workflow.add_conditional_edges(
"extract_issue_data",
router,
{
"create_ticket": "create_ticket",
"request_more_info": "request_more_info"
}
)
workflow.add_edge("create_ticket", END)
workflow.add_edge("request_more_info", END)
return workflow.compile()And let’s put it all together. Let’s create a Fast API server that runs the previously defined workflow every 30 seconds, thus starting the automatic email processing
from contextlib import asynccontextmanager
from fastapi import FastAPI, BackgroundTasks
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from apscheduler.triggers.interval import IntervalTrigger
import uvicorn
from dotenv import load_dotenv
from ai import build_issue_workflow_graph
from mail import get_unread_messages_with_threads
scheduler = AsyncIOScheduler()
@asynccontextmanager
async def lifespan(app: FastAPI):
scheduler.start()
yield
scheduler.shutdown()
app = FastAPI(lifespan=lifespan)
@scheduler.scheduled_job(trigger=IntervalTrigger(seconds=30))
async def process_emails():
print("Email processing started")
processed_emails = get_unread_messages_with_threads()
graph = build_issue_workflow_graph()
for email in processed_emails:
initial_state = {
"email_id": email["email_id"],
"email_conversation": email["email_conversation"],
"need_more_information": False,
"additional_info_needed": "",
"project_id": 0,
"name": "",
"description": "",
"mail_subject": email['subject'],
}
final_state = graph.invoke(initial_state)
print(final_state)
print("Email processing end!")
@app.post("/start-email-processing")
async def start_email_processing(background_tasks: BackgroundTasks):
background_tasks.add_task(process_emails)
return {"message": "Manual started"}
if __name__ == "__main__":
load_dotenv()
uvicorn.run(app, host="0.0.0.0", port=8000So let’s test the solution with the following email I sent with an attachment.
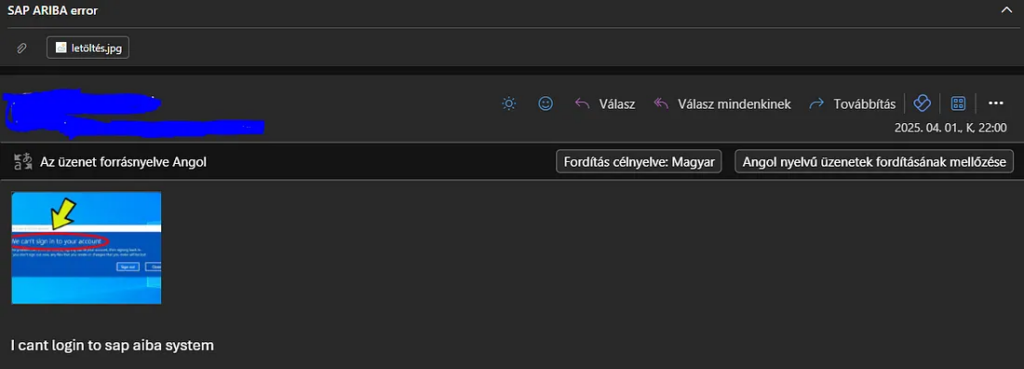
And the following ticket was created in Jira.
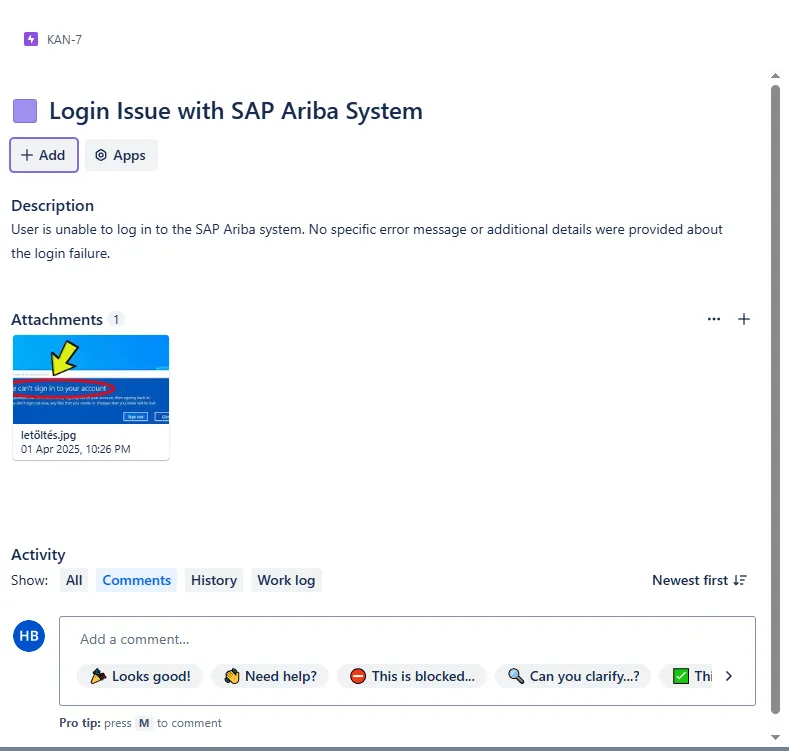
In this article, we built an efficient AI agent that can analyze customer emails and automatically create Jira tasks.
Vélemény, hozzászólás?